/
Blog







7 Essential Caching Strategies to Boost Backend Performance and Scalability
Discover 6 powerful caching strategies to enhance backend performance and scalability. From in-memory and distributed caching to hybrid solutions, learn how to implement effective caching in your backend architecture for faster response times and optimized resource use

8 min read
0 Views
1. In-Memory Caching
Description: Stores frequently accessed data in the application’s memory, which speeds up access since the cache is within the application’s process.
Mechanism:
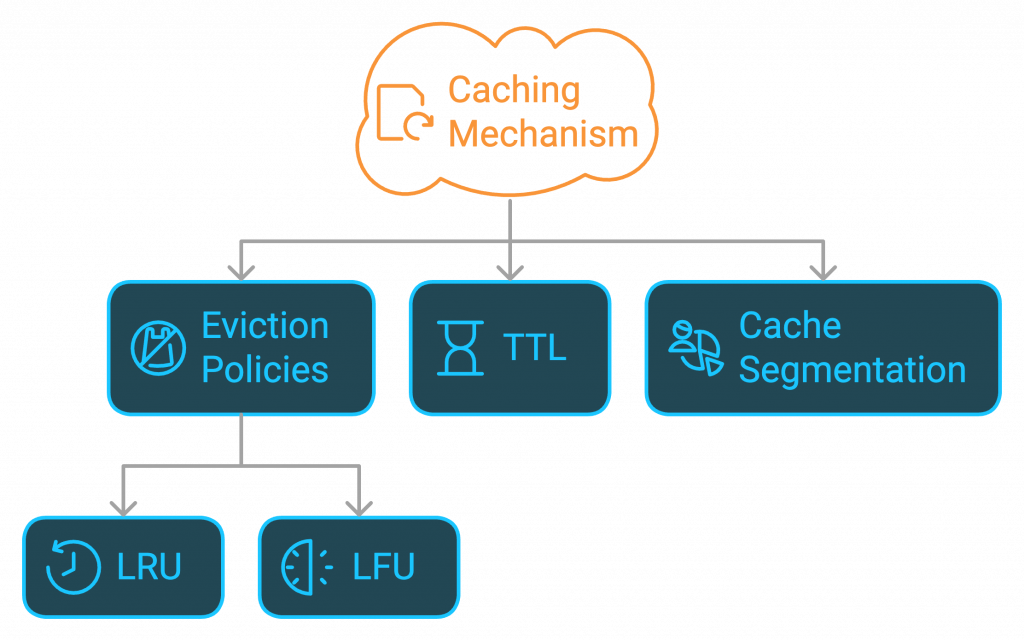
- Implements policies like LRU (Least Recently Used) or LFU (Least Frequently Used) for cache eviction.
- TTL for auto-expiration of cache entries.
- Segmentation of cache by data types.
Setup:
- Use libraries like node-cache or lru-cache in Node.js.
- Define maximum cache size and TTL settings.
- Set up policies for cache invalidation based on data patterns.
Advantages:
- Very fast access due to in-process storage.
- Simple to implement with minimal setup.
- Minimal latency for frequently accessed data.

Disadvantages:
- Limited scalability and persistence.
- Can consume high memory within the application.
- Not ideal for distributed systems or large datasets.

Example:
const NodeCache = require('node-cache');
const cache = new NodeCache({ stdTTL: 100 });
// Set cache
cache.set('user_123', { name: 'Alice', age: 30 });
// Retrieve cache
const user = cache.get('user_123');
2. Distributed Caching (e.g., Redis)
Description: A centralized caching solution accessible by multiple services. Often achieved through distributed caching software like Redis, enabling caching across multiple application instances.
Mechanism:
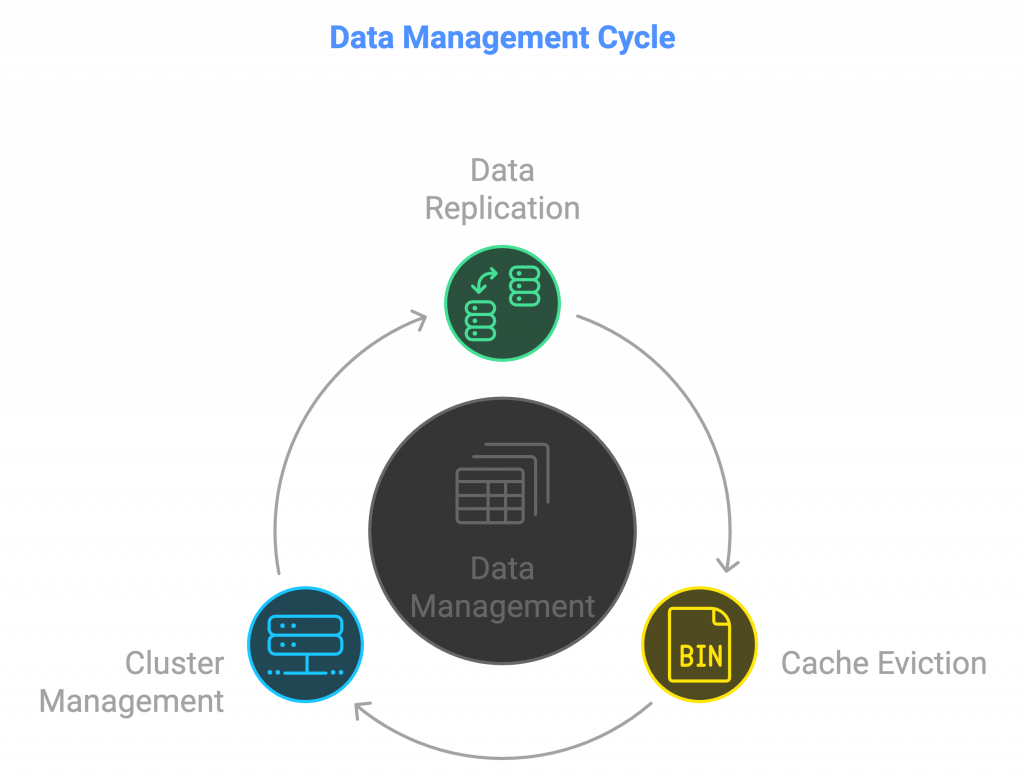
- Data is replicated or sharded across multiple servers.
- Cache eviction policies and TTL for expiring stale data.
- Cluster management for distributed access and redundancy.
Setup:
- Install and configure Redis in cluster mode.
- Use libraries like ioredis for Node.js to connect to the cache.
- Configure master-slave replication for failover support.
Advantages:
- Scalable and supports distributed access.
- Persistent options for data durability.
- High availability with Redis clustering and replication.

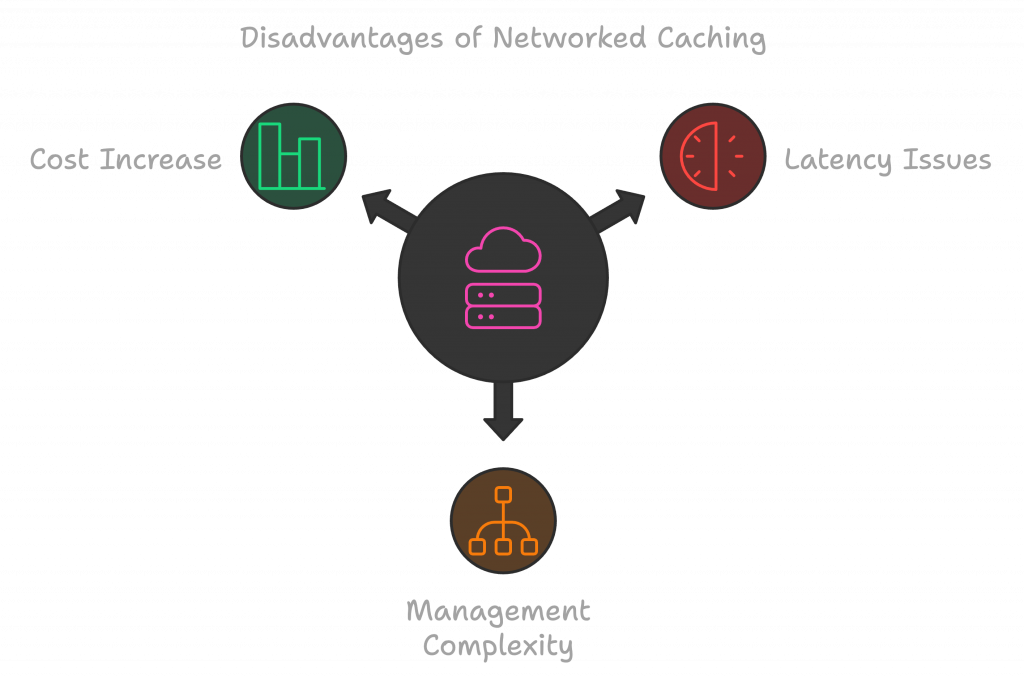
Disadvantages:
- Requires network access, adding latency.
- More complex to manage compared to in-memory caches.
- Costs may increase with large clusters.
Example:
const Redis = require('ioredis');
const redis = new Redis();
// Set cache
await redis.set('user_123', JSON.stringify({ name: 'Bob', age: 25 }));
// Retrieve cache
const user = JSON.parse(await redis.get('user_123'));
3. Application-Level Caching (e.g., Cache Libraries)
Description: Application-level caching uses libraries that enable in-app data caching, giving developers full control over TTL and cache configuration.
Mechanism:
- Custom cache invalidation rules based on app logic.
- Data segmentation with TTL and invalidation methods.
- Warming mechanisms for preloading important data.

Setup:
- Use libraries like memory-cache in Node.js.
- Set up cache regions or segments for data types.
- Customize TTL and invalidation policies for each cache entry.
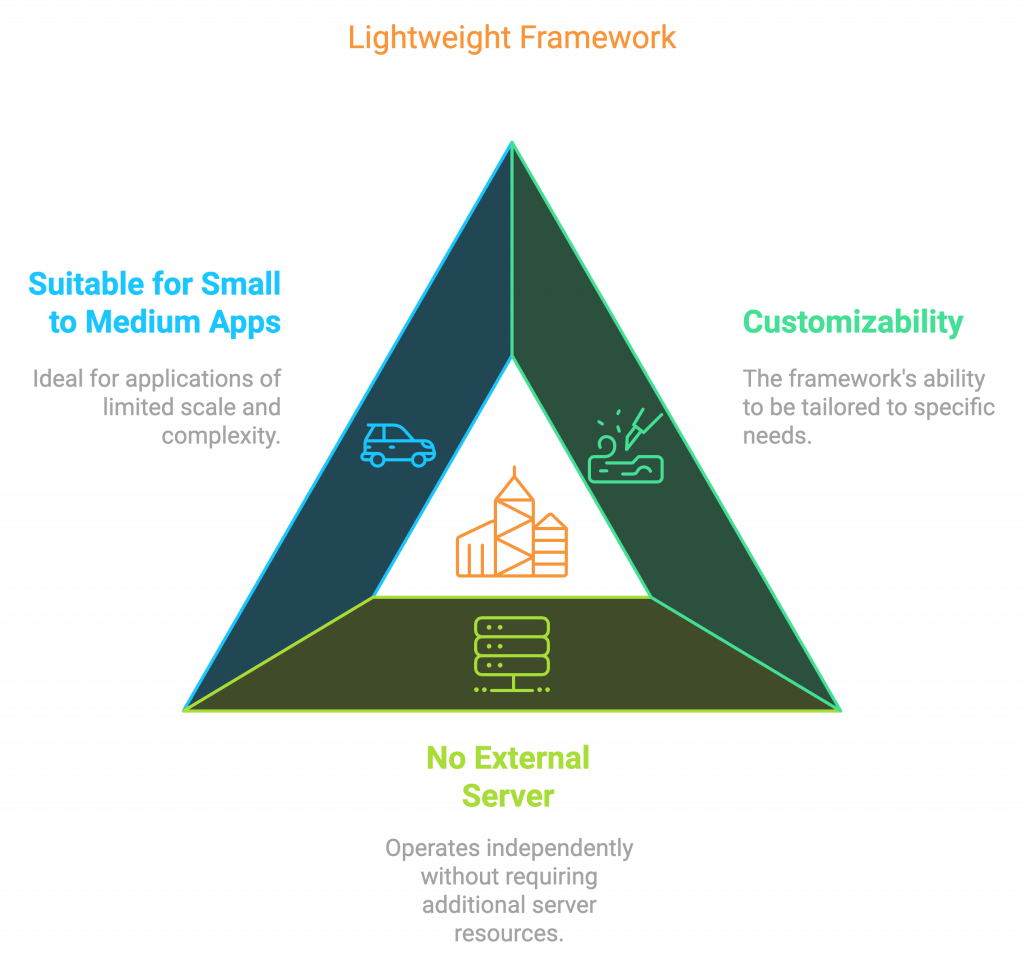
Advantages:
- Highly customizable.
- Lightweight, no external server needed.
- Good for small to medium applications.
Disadvantages:
- Limited scalability to a single application instance.
- Not suitable for distributed access.
- Memory-intensive for large data volumes.
Example:
const cache = require('memory-cache');
// Set cache
cache.put('product_456', { name: 'Laptop', price: 1500 }, 30000);
// Retrieve cache
const product = cache.get('product_456');
4. Database Caching (Materialized Views, Query Caching)
Description: Database-level caching stores frequently accessed data or query results directly in the database, reducing repeated queries.
Mechanism:
- Materialized views for precomputed data retrieval.
- Query result caching for expensive queries.
- Use of read replicas for distributed load handling.

Setup:
- Set up materialized views for commonly accessed query data.
- Configure query caching (e.g., MySQL query cache).
- Configure read replicas in the database.
Advantages:
- Integrated within the database.
- Reduces repetitive queries and load on the main database.
- Maintains data consistency with minimal configuration.

Disadvantages:
- Higher load on the database server.
- Limited cache control and flexibility.
- Slower than in-memory caching solutions.

Example (Materialized view in PostgreSQL):
CREATE MATERIALIZED VIEW popular_products AS
SELECT * FROM products WHERE views > 1000;
5. CDN (Content Delivery Network) Caching
Description: CDN caching stores static content like images, stylesheets, and scripts at edge locations closer to the end-user, reducing server load.
Mechanism:
- Replication of static assets to CDN edge nodes.
- Cache expiration through HTTP headers.
- Use of cache invalidation for updated content.

Setup:
- Configure a CDN (e.g., Cloudflare or AWS CloudFront).
- Set Cache-Control headers on HTTP responses for cache expiry.
- Set up automatic cache invalidation when content is updated.
Advantages:
- Fast access for globally distributed users.
- Reduces load on the origin server.
- Provides resilience against traffic spikes.

Disadvantages:
- Suitable mainly for static resources.
- Additional cost for CDN services.
- May serve stale data if not invalidated.

Example (Cache-Control headers):
Cache-Control: max-age=31536000
6. HTTP Caching (Browser and Proxy Caching)
Description: HTTP caching enables client-side and intermediary caches to store frequently accessed content, improving speed and reducing server load.
Mechanism:
- Cache-Control and ETag headers manage data freshness.
- Vary headers enable cache customization.
- Use of conditional GET requests.

Setup:
- Configure HTTP headers (Cache-Control, ETag, Last-Modified).
- Implement policies for different resource types.
- Use middleware like helmet in Node.js for easier configuration.
Advantages:
- Offloads server processing for repeat visitors.
- Simple to implement with HTTP headers.
- Works without needing additional infrastructure.

Disadvantages:
- Limited to client and proxy caching.
- Less control over cache expiration.
- Can result in serving stale content.

Example:
Cache-Control: public, max-age=86400
ETag: "some-unique-id"
7. Hybrid Caching
- Description: Combines multiple caching techniques, such as in-memory and distributed caching, to optimize access speed across different data types.
Mechanism:
- Multi-level caching for frequent data access.
- Adaptive caching policies per level.
- Fallback mechanisms for cache misses.

Setup:
- Configure an in-memory cache as the first level and Redis as the second level.
- Set different TTLs for each cache layer.
- Use custom logic to fall back to the secondary cache if the primary misses.
Advantages:
- Balances speed, scalability, and consistency.
- Minimizes network requests with local cache.
- Suitable for handling both static and dynamic data.

Disadvantages:
- Complex setup and configuration.
- Higher infrastructure and management costs.
- Can be difficult to debug across layers.
Example:
// First level: In-memory cache
const memoryCache = new NodeCache();
// Second level: Redis cache
const redis = new Redis();
async function getData(key) {
let data = memoryCache.get(key);
if (!data) {
data = await redis.get(key);
if (data) memoryCache.set(key, data);
}
return data;
}
Comparison
| Factor | In-Memory Caching | Distributed Caching | CDN Caching | HTTP Caching | Database Caching | Hybrid Caching |
|---|---|---|---|---|---|---|
| Latency | Very low, data is stored within the app instance | Low, but some network latency due to distribution. | Low for static content as it’s closer to the user. | Low, leverages browser and intermediary caches. | Moderate, depends on database speed. | Low, combines multiple levels for balanced latency. |
| Scalability | Limited by single-instance memory capacity. | High, scales with clustering and sharding. | Very high, distributed globally on edge servers. | Moderate, limited by cache size and expiration. | Moderate, can scale with read replicas. | High, flexible scaling across in-memory and distributed. |
| Persistence | None, cache clears on app restart. | Optional persistence (e.g., Redis). | None, data is temporary for quick access. | None, generally non-persistent. | Persistent, data resides in the database. | Persistence varies based on in-memory and distributed use. |
| Complexity | Simple, minimal configuration required. | Moderate to high, requires cluster management. | Moderate, needs CDN setup and integration. | Low, managed by the browser or proxy cache. | Low to moderate, involves database query tuning. | High, needs coordination across caching layers. |
| Use Case Suitability | Best for single-instance apps needing quick access. | High-traffic, distributed, or microservices apps. | Static, globally accessed content (e.g., images). | Enhancing user experience with cached page loads. | Reducing load on database with frequent query access. | Applications needing both fast access and scalability. |
FAQs I got while interviewing:
Question 1: Can you explain what caching is and why it’s important in backend systems?
Answer:
Caching is the process of storing copies of frequently accessed data in a faster storage medium (e.g., in-memory or distributed caches) to reduce the time it takes to retrieve this data in future requests. The primary purpose of caching is to improve the performance of applications by reducing the load on backend systems such as databases or external services, and to lower response times for end-users. Caching is especially useful in high-traffic applications where the same data is repeatedly requested.
Question 2: What are the different types of caching techniques, and when would you choose one over the other?
Answer:
The main caching techniques are:
- In-Memory Caching: Stores data directly in the memory of the application. It’s ideal for fast access to frequently requested data on a single server or instance.
- When to use: Small applications or for single-instance setups with rapid access requirements.
- Distributed Caching: Uses external cache systems like Redis or Memcached to share cached data across multiple instances.
- When to use: In microservices or high-traffic applications that need to scale horizontally.
- CDN Caching: Used for static content like images, videos, and stylesheets, stored in distributed edge servers.
- When to use: For serving globally distributed static content to reduce load times.
- HTTP Caching: Relies on cache-control headers and browsers to cache responses for faster repeated access by users.
- When to use: For caching responses to improve page load times in web applications.
- Database Caching: Caches frequently queried data within the database system itself to offload repetitive read queries.
- When to use: In applications with high database read traffic that needs performance improvements.
- Hybrid Caching: A multi-tier approach, combining in-memory caches with distributed caches.
- When to use: When you need both fast access for hot data and scalability for larger datasets.
Question 3: How do you handle cache invalidation in distributed systems?
Answer:
Cache invalidation in distributed systems is crucial to ensure that stale data isn’t served to users. Here are some common strategies:
- Time-based Expiration: Set an expiration time for cached data (TTL) so that it’s automatically invalidated after a specified duration.
- Example: Use Redis EX option to set TTL when storing data.
- Manual Invalidation: Manually delete or update cached entries when the underlying data changes (e.g., after an update or delete operation).
- Example: Clear the cache when a record is updated in the database.
- Versioning: Store versioned keys, so each update to data involves creating a new cache key, allowing old versions to be evicted or expire naturally.
- Example: Use a version number as part of the cache key.
- Publish/Subscribe: Use a publish/subscribe mechanism to notify other services or instances when a cache needs to be invalidated. For example, Redis supports pub/sub to broadcast cache invalidation events.
Question 4: What are the trade-offs when using hybrid caching in a distributed system?
Answer:
Hybrid caching involves combining multiple caching strategies, such as in-memory caching and distributed caching, to achieve both speed and scalability. Some trade-offs include:
- Advantages:
- Flexibility: You can store hot data (frequently accessed) in memory for fast access and use a distributed cache (e.g., Redis) for larger datasets that require horizontal scalability.
- Optimized for Different Data: Frequently accessed data can be cached locally, reducing access times, while less frequently used data is stored in distributed caches to ensure scalability.
- Failover Mechanism: If one caching layer fails, you still have another layer (e.g., Redis) that can serve cached data, improving resilience.
- Disadvantages:
- Increased Complexity: Managing multiple caching layers adds complexity in terms of consistency, invalidation strategies, and monitoring.
- Overhead: Maintaining multiple caches can introduce overhead in terms of memory usage, network traffic, and latency.
- Data Inconsistency: Ensuring that the data in both caches is synchronized can be challenging, especially when dealing with cache invalidation.
Conclusion
Each caching strategy has its own strengths and weaknesses, and the choice ultimately depends on the specific requirements of your application. Here’s a summary of recommendations:
- For Fast Access with Minimal Setup: In-Memory Caching is the best choice for single-instance applications or small-scale systems that need quick access to data with minimal configuration.
- For Distributed, High-Volume Applications: Distributed Caching (like Redis) is ideal for applications that scale horizontally and need shared access to cached data across multiple services or instances. Its clustering and sharding capabilities make it a robust solution for distributed environments.
- For Reducing Database Load: Database Caching with materialized views and query caching works well in scenarios where database queries are a significant bottleneck, allowing frequently accessed data to be served without repeated query execution.
- For Global Content Distribution: CDN Caching is unmatched in delivering static content to a geographically distributed audience, reducing load times significantly for global users.
- For User-Specific and Session Data: HTTP Caching in the browser can speed up page loads for individual users by caching static assets or specific responses.
- For Comprehensive, Multi-Tiered Caching Needs: Hybrid Caching allows for a layered approach where frequently accessed data is stored in-memory, while less critical data is managed in a distributed cache. This combination maximizes speed and scalability, although at a cost of increased complexity.

Final Recommendation: For many backend systems, Distributed Caching (Redis) provides a balanced solution for both scalability and speed. If you anticipate further scaling needs or a microservices architecture, combining Distributed Caching with Hybrid Caching (a multi-level approach) could ensure optimal performance and availability.

Related Posts

Overview: The Critical Role of Images in Modern Web Development Images are fundamental to web experiences, accounting for approximately 50% of a typical webpage’s total size. How you choose to render these assets significantly impacts user experience, page performance, and search engine rankings. As web technologies evolve, developers have multiple options for implementing images in […]

A high-performance React component that creates an engaging coin celebration animation using Framer Motion. Features dynamic particle systems, smooth transitions, and interactive effects perfect for gaming applications, reward celebrations, and interactive web experiences. Built with React 18+ and Framer Motion.

Learn how distributed caching with Redis can boost backend performance and scalability. This guide covers setup, caching strategies, and a step-by-step technical demo with benchmarks.
Subscribe to our newsletter
Get the latest posts delivered right to your inbox